Vortrainierte KI-Modelle für Bilder und Texte
Ein Problem mit dem KMU regelmäßig konfrontiert werden, wenn sie Künstliche Intelligenz (KI) für ihre Zwecke einsetzen wollen, liegt in den fehlenden technischen Ressourcen. Ein Unternehmen, das beispielsweise eine automatisierte Qualitätskontrolle der Produktion mittels aufgenommenen Bilder durchführen möchte, benötigt normalerweise mehrere 10.000 Bilder oder sogar mehr, um ein gut funktionierendes Neuronales Netz zu trainieren.
Nicht nur die schiere Menge an benötigten Bildern stellt ein Problem dar, sondern vor allem auch das Training des Neuronales Netzes an sich. Die Komplexität ist so hoch, dass der Computer enorm viele Rechenschritte ausführen muss, um gute Ergebnisse zu erzielen. Mit den Ressourcen, die einem durchschnittlichen KMU zur Verfügung stehen, ist dies ein aussichtsloses Unterfangen, da das Training des KI-Modells Monate oder gar Jahre benötigen würde.
Ganz ähnlich sieht es bei Unternehmen aus, die natürliche Sprache verarbeiten wollen. Das Training von Sprachmodellen übersteigt die Kapazität von KMU meist bei weitem. So werden diese Modelle mit mehreren Gigabyte großen Datensätzen aus z. B. der Wikipedia oder wissenschaftlichen Artikeln „gefüttert“, die für normale Computer bei weitem nicht bewältigbar sind.
Also was kann man als KMU dagegen tun? Glücklicherweise gab es in diesem Bereich in letzten 7-10 Jahren enorme Fortschritte von großen Technologiekonzernen, die die entsprechenden Rechenkapazitäten zur Verfügung haben. Google, Meta (Facebook), IBM, Microsoft, etc. haben vortrainierte KI-Modelle für die Bildverarbeitung und die Analyse von natürlicher Sprache entwickelt, die sie anderen Unternehmen frei überlassen. Mithilfe dieser Modelle lassen sich die aufwändigen Aufgaben auch für KMU mit begrenzten Ressourcen bewältigen. Durch die Nutzung vortainierter KI-Modelle werden weniger Bilder und Texte sowie deutlich weniger Rechenleistung benötigt, Bilder und Texte klassifizieren zu können.
Aus diesen Gründen werden im folgenden einige vortrainierte Modelle genannt, die sehr leicht von KMU für ihre Zwecke angepasst und anschließend verwendet werden können.
Für die Klassifikation von Bildern sind die Modelle VGG und ResNet inkl. ihrer Abwandlungen wahrscheinlich die bekanntesten. Sie dienen als guter Ausgangspunkt, da sie viele vortainierte Bilder umfassen und leicht über Keras/Tensorflow und PyTorch nachtrainiert und verwendet werden können. Keras/Tensorflow ist eine Programmierumgebung für Künstliche Intelligenz von Google – PyTorch von Meta (Facebook). In der ersten Spalte von Tabelle 1 steht der Name des Modells.
Die zweite Spalte (Size (MB)) ist die Größe des vortrainierten Modells in Megabyte. Die Spalte „Top-1 Accuracy“ gibt an, mit welcher Genauigkeit das KI-Modell ein Bild vorhersagt. „Top-5 Accuracy“ gibt an, mit welcher Genauigkeit das gesuchte Bild unter den fünf besten vorgeschlagenen Bildern des KI-Modells erkannt wird. In der Spalte „Parameters“ ist die Anzahl der verwendeten Parameter des Modells angegeben. Umso größer die Anzahl der Parameter, desto komplexer ist das Modell. Die Tiefe („Depth“) zeigt die Anzahl der Hidden Layers des Modells an.
Etwas spielerischer gibt sich in Abbildung 1 die Übersicht über die bekanntesten Sprachmodelle. Da diese oft nach den Figuren aus der Sesamstraße benannt werden, finden sich dort auch die entsprechenden Gesichter. Die Namen stehen dabei für Abkürzungen. So steht z. B. der Name des Sprachmodells von Google BERT für „Bidirectional Encoder Representations from Transformers“.
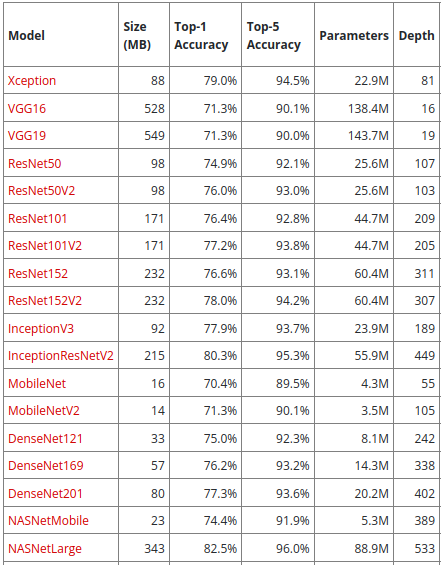
Tabelle. 1: Übersicht über einige der bekanntesten Modelle für Analyse und Klassifikation von Bildern. (Quelle: https://keras.io/api/applications/)
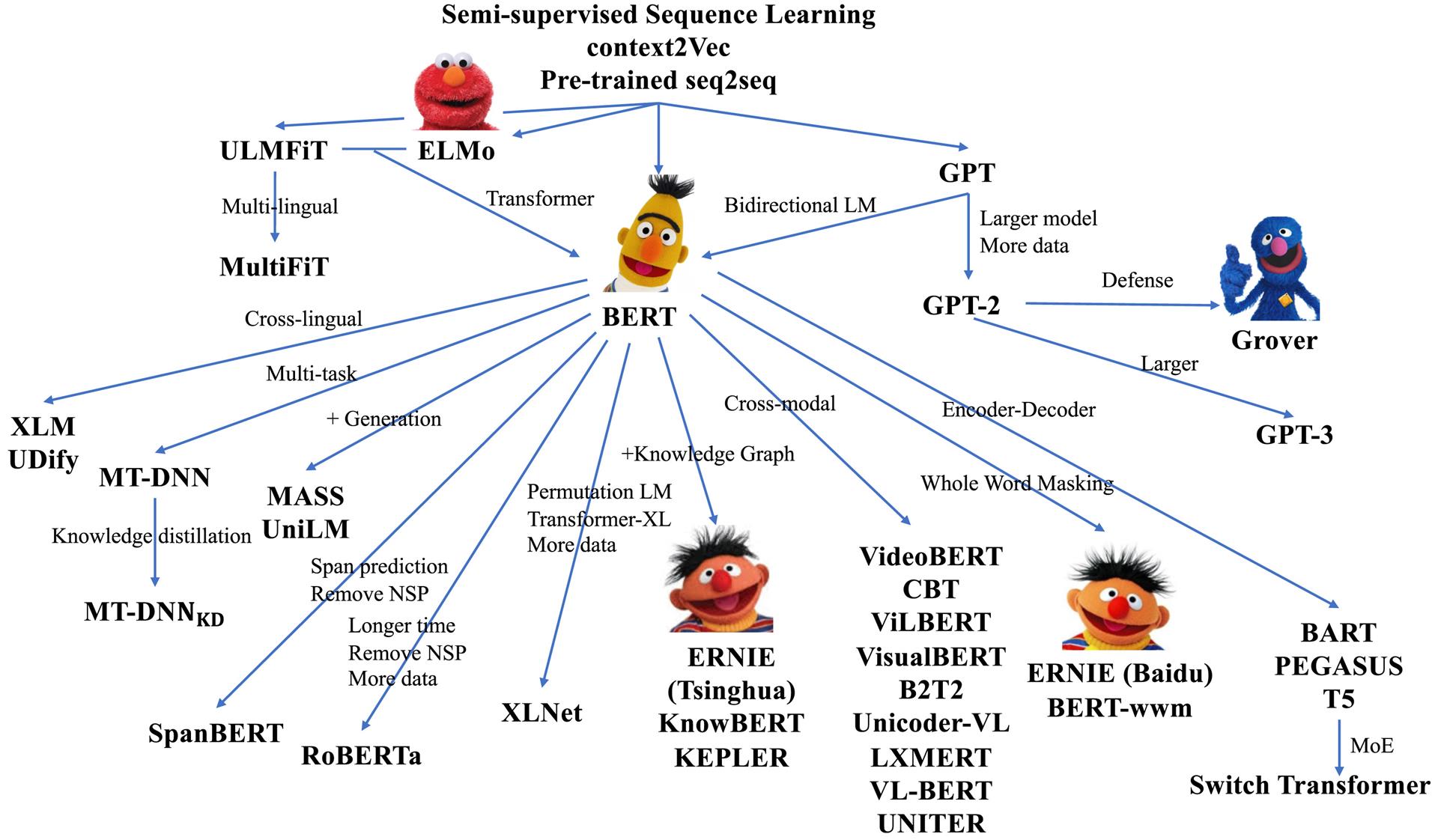
Abbildung. 2: Übersicht über die bekanntesten Sprachmodelle. (Quelle: Han et al. 2021)
Qellen: Han, Xu, et al. (2021):Pre-trained models: Past, present and future. AI Open 2 (2021): 225-250.
www.keras.io